Advice for ML students
Work in progress: I will try to regulary update this page with more information. Please, send me an e-mail if you feel like something is missing.
This page contains my personnal advice to (future) students in our Artificial Intelligence Master at Paris-Saclay, but I hope it will also be useful for other students. It is obviously highly biased toward sub-domains that I know, for example I will cover Natural Language Processing but not Computer Vision. This guide is not intended to be exhaustive but instead to focus on the smallest possible list of recommendations so that you don't feel overwhelmed.
Outline:
Background: topics you are supposed to know — don't worry if you have gaps in this list, the goal of this page is to help you identify what you need to focus on! Take your time in the first months of the master to work on subjects you don't know yet;
Helpful resources
Searching and applying for an academic internship or PhD
Overview of some ML for NLP research topics: a few references to give an overview of important topics in Machine Learning for Natural Language Processing for students who want to start a PhD.
Importantly, and I cannot stress it enough: do not pay for online courses. Do not pay for online courses. Do not pay for online courses. Do not pay for online courses. Do not pay for online courses. Do not pay for online courses. Do not pay for online courses. Do not pay for online courses. DO NOT PAY FOR ONLINE COURSES.
If you are a (future) student in our master and you fail to find one of the book/article listed here, please contact me by e-mail.
Background
Formalisation
It is really important that you learn to formalize your ideas using math and pseudo-code. Pictures are good for the intuition but:
they can be misleading,
they should only be used to give the general idea which then must be correctly formalized.
Of course there are many counter examples, e.g. probabilistic graphical models which have a well defined “graphical semantic”.
Let's take a concrete exemple: how to present a multilayer perceptron (MLP)? (do not worry if you don't know what a MLP is, you will learn that in the deep learning course) This simple and common deep learning architecture is often presented using this kind of figure:
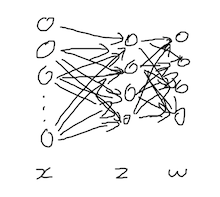
Unfortunately, this picture doesn't say much and it is not precise. I doesn't fully specify what is the computation done by the model. A good way to present it would be:
Let \(x \in \mathbb R^n\) be an input vector. A multilayer perceptron with a single hidden layer computes an output logit vector \(w \in \mathbb R^m\) as follows:
\[ z = \tanh(A^{(1)} x + b^{(1)}) \\ w = A^{(2)} z + b^{(2)} \]
where:
the hyperbolic tangent \(\tanh\) is applied element wise,
\(z \in \mathbb R^h\) is a hidden representation of size h,
\(A^{(1)} \in \mathbb R^{h \times n}\) and \(b^{(1)} \in \mathbb R^h\) are the parameter of the hidden projection,
\(A^{(2)} \in \mathbb R^{m \times h}\) and \(b^{(2)} \in \mathbb R^m\) are the parameter of the output projection.
If you are not familliar with matrix multiplication it can be helpful to draw the matrices to keep track of dimensions — do it on paper when you code so you are not lost!
This kind of drawing may become more important when you will need to rely on implicit broadcasting.
Programming
The main language you will need during this master is Python, which is really popular in machine learning and datascience in general. There are many other popular languages including C, Rust and Julia, but you will have plenty of time to learn them when you will need to use them. For example, C is still used to design specific components in machine learning architectures that require speed and cannot be parallelized easily on GPU. However, in general and in the context of this master, focus on Python: learn how to write programs in Python, how it differs from languages you already know (e.g. loop definition in Python is unusual!) and play with it. It's a computer science master, therefore strong programming skills is a requirement. I strongly advise to NOT spend time learning how to use fancy new languages or libraries. Use the basic libraries that works well and are well documented.
There are two important libraries that you will need to use:
Numpy: for scientific computation,
Matplotlib: for visualization.
Play with them, train yourself to write programs that manipulate vectors/matrices and display graphs. During the master you will probably use Pytorch and Pandas, but start with these two first and once you are proficient with them it will be easy for you to use the others.
A commonly used tool to prototype Python scripts is Jupyter. Install it and use it: most of your lab exercises will be based on Jupyter notebooks.
Linear algebra
Linear algebra is a recurring topic in machine learning and datascience: it will appear everywhere. Yes, everywhere. Having a good understanding of linear algebra will help to understand many algorithms and analysis techniques really quickly. You will save a lot of time right now and later. If you did not study it as an undegrad or if you need to refresh your memory, I can only advise you to watch and study Gilbert Strang's course which available online for free:
on OCW: https:ocw.mit.educoursesmathematics18-06-linear-algebra-spring-2010video-lectures/
on Youtube: https:www.youtube.com/watch?v=J7DzL2_Na80&list=PLE7DDD91010BC51F8&index=2
My advice is to study topics covered until (and including) lecture 21. However, it is long and you may not have time to study everything. Don't despair if you can't do it all, watching only a few of the videos will already do you a big favor (but watch them in order!).
Probabilities/statistics
Alex Tsun uploaded a set of 5 minutes videos on probability that can be useful to understand the main concepts:
Latex
In computer science, we formalize and expose our work using mathematics and pseudo-code. You must learn to write reports than contains math and (pseudo-)code nicely, do not display screenshots from other people reports. The common tool for this is latex, there are many software available, I recommend:
The Overleaf website contains a nice Latex tutorial and an introduction on writing math in Latex. Write you tex files like you write code:
one sentence per line in general, break longer sentences in several lines
use indentation (for example to delimit environments)
write comments!
An important feature of Latex is that it takes care of the layout for you. Do not use \\ to break lines or create a new paragraph: just leave one empty line for a “short paragraph break” and \paragraph{} for a “long paragraph break”.
A few tips:
use the align environment to align your equations
use the intertext command to write text between aligned equations to help the reader
the detexify online tool can help you finding how to write a specific symbol in latex
the math_commands.tex file is useful to write math with proper notation, see the PDF example and its source. Basically, this package introduces short commands like \va and \vb for vectors named a and b, respectively, and \eva_i and \evb_j when you want to reference elements i and j of vectors a and b (the v means vector, ev means element of vector). For matrices, its usual to use capital letter, so the commands are of the form \mA and \emA.
It is important to write clearly, here are a few useful links:
Jason Eisner's page on dissetartation writing — the title indicates that its for PhD thesis, but I think it contains useful information for writing other kind of reports too
Helpful resources
Here is a list of books you can use as a resource when you are searching for a specific topic related to machine learning:
Probability & Statistics with Applications to Computing (Tsun)
Mathematics for Machine Learning (Deisenroth, Faisal and Ong)
Linear Algebra Done Right (Sheldon Axler)
Pen and Paper Exercises in Machine Learning (Michael U. Gutmann)
We usually accept reports both in french and english (but check with the course teacher first!). However, if you are in a group with non-french speakers, you don't really have a choice. The following websites can help you to improve your English writing:
DeepL: an online translator;
Linguee: search for small portion of text in bilingul corpora. This is useful if you want to check what are common patterns in English.
Searching and applying for an academic internship or PhD
Open positions are usually advertised on mailing lists. You should register to them, note however that you will receive many emails (use Thunderbird to deal with your emails instead of a web client).
french NLP mailing list, many positions in industry and academia in France are advertised there: ln-atala
french ML mailing list: proml
international NLP mailing lists: corpora, sig-irlist, winlp
internationa ML lists: ml-news, rl-list, wiml, queer in ai, black in ai
A few websites you can also check to find PhD positions:
Attach a CV when contacting a researcher. A few tips:
there is no page limit, however 1-2 pages is common for a master student
use a plain simple template, something that looks like a list is totally fine, e.g. something like this. Do not spend time trying to fancy your CV layout, academics are conservative, they like to see layouts that they know and are easy to follow.
if you did internships in academia, specify the lab, the team, who you worked with and write something about your work there (even use a few lines of text CV if you want). Here is what I used to have when I was searching for a PhD, but this is the bare minimum, writing a few lines to explain your work is even better:

more information is better than less, but focus on important information (e.g. nobody cares about the Shangai ranking of your uni, courses that you followed and succeeded that are related to the position you are applying to are way more important)
it's 100% fine to not have any publication when applying to a PhD (most students don't!), but you should add information about courses you took/project you worked on related to your research interests — don't put everything, limit to what interested you most and is related to positions you are applying to. For example, I used to have a “School projects” section in mine (again, you can also add a few lines to explain what these projects are, add a github link, etc.):

indicate in your header what are the fundamental topics you are interested in! Here is the head of my CV (the quantity here doesn't matter, just be honest, these are the subjects you want to focus on for several years!)

It is also best to have a public website with the same information. You can do something quickly with a static website generator like Hugo, Pelican or Jemdoc. If you don't want to self-host your website, you can also use free services like Cygale or Github pages.
Overview of some ML for NLP research topics
This section is intended for students who aim for a PhD after the master. Scientific research is exciting and fascinating, especially in machine learning which is a popular field these days. However, it is difficult to have a clear view of what are interesting and open research problems. I will try to list a very limited number of them that are highly biased toward what I am personnaly interested in. It is important to understand that “solving task X with machine learning” is vague and this kind of objective may limit the area in which you will contribute as a computer science researcher. This is especially true in natural language processing where obtaining good results for well studied languages is straightforward with large pretrained models like Bert and GPT. But first, the most important advice is the following:
I recommend reading the How to Find Research Problems page by Jason Eisner and references therein.
Structured prediction
Prediction problems you will study during the master will mainly be either (binary) classification and regression. However, there are many other problems including structured prediction problems where:
the output space depends on the input,
the output space is often of exponential size, meaning you can't enumerate all possible outputs quickly,
the weight of an output decomposes into parts.
One of the most basic example in natural language processing is syntactic dependency parsing. Assume you have an input sentence of \(n\) words. The goal is to predict the bilexical dependencies between words which can be represented as a spanning arborescence in a graph.
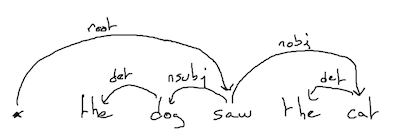
A graph based parser for this problem works as follow:
Build a graph where each word in the sentence is represented as a vertex;
use a neural network to weight each possible arc (i.e. dependency between two words);
compute the spanning arborescence of maximum weight.
Other problems include summing over all possible spanning arborescences which is required for training via a maximum likelihood loss. As such, structured prediction is a research field that includes many computer science topics, including graph theory, formal grammars and (combinatorial) optimization:
How to represent linguistic content in structures that are appriorate for prediction? link
How to efficiently decode the structure of maximum weight? Constituency parsing was originaly mainly tackled via formal grammars, but nowadays span-based approaches are prefered. In some cases, polynomial time algorithms may not exists or they are too expensive, hence we rely on combinatorial optimization approaches. link 1 link 2 link 3 link 4
If you are interested in structured prediction, Jason Eisner's research summary gives a good view of the field.
Designing neural architectures
In order to train and use a neural network, one must first design its architecture which can be motivated in many ways. For example, LSTMs have been designed to prevent the vanishing gradient problem and Transformer for their ability to be efficiently parallelized on GPU. However, they can also be designed to inject prior knowledge about the task so that they are more data efficient or interepretable:
Convolutional Neural Networks where motivated by translation equivariance in computer vision problems, which has been extended to group equivariance including symmetry and rotation; link
The same technique has been used in natural languages processing for compositional generalization; link
Discrete structures are usually used to describe natural languages (syntax, discourse structure, word alignment between a sentence and its translation, etc) so there has been an interest in introducing differentiable approximation of combinatorial problems in neural networks; link 1 link 2 link 3 link 4
General differentiable optimization layers have been proposed, which can also learn the optimization problem constraints; link 1 link 2 link 3
Introducing logical reasoning into a neural network via a differentiable SAT solver. link
Expressivity of neural architectures
Computer scientists have developed formal tools to classify the expressivity of formal languages and the hardness of problems, see for example wikipedia pages of Chomsky hierarchy and mildly context-sensitive grammar formalism for the case of formal grammars and complexity class for algorithms. Although the universal approximation theorem states that any function can be approximated by a neural network under certain conditions, researcher have been interested in better characterizations of architectures used in practice (e.g. with fixed width) and using other theoretical tools:
Skip-gram word embedding model as been shown to be equivalent to matrix factorization; link
Reccurent neural networks can be classified according to the complexity of the network memory and their capacity to be described by Weighted Finite-State Machines; link
Self-attentive networks/Transformers cannot model hierarchy, which led to interest in quantifying how well they can approximate it via Dyck languages, for example; link 1 link 2 link 3
Comparaison of autoregressive, latent-variable autoregressive and energy-based models in term of expressiveness in the output distributions. link
Efficient computation
Computational power is expensive. A good GPU for machine learning cost at least 5.000 euros, but a reasonable one for today's neural architectures would be closer to 10.000 euros (e.g. NVidia v100 with 32Go of RAM). State-of-the-art models are usually trained on very large datasets with several GPUs or even TPUs. This is not sustainable and prevent the use of neural networks on small embedded devices. It is therefore important to develop more efficient models both in terms of memory and computational time. If you are interested in this subject, check Kenneth Heafield's webpage.
Neural networks are usually implemented with autograd libraries like pytorch that take care of the computation of the gradient automatically. In theory, the backpropagation algorithm as a time complexity of the same order as the forward pass that was used to build the computational graph (more precisely: at most 5 times the cost of evaluating the forward function). However, in some specific cases this can be done more efficiently, for example:
The default algorithm to compute the gradient for Online Recurrent Neural Networks as a \(\mathcal O(n^4)\) complexity, but it has been shown that it can actually be combuted in cubic time; link 1 link 2
More recently, an optimal algorithm to compute high-order derivatives of Weighted Finite-state Machines has been proposed, which is several order of magnitude faster than backpropagation for this problem. link
Other methods to improve computation time include, among others:
Networks that have a block sparsity structure; link
Learning with sparsity inducing regularization; link
Efficient variations of a given architecture through randomization, low rank constraints, etc; link
Quantization to rely on bit operations instead of floating point operations at test time. link 1 link 2
Learning algorithms beyond gradient descent
First order optimization methods are popular in machine learning as they are scalable.
The idea of adaptive stepsize has been very popular in the deep learning community and many algorithms have been proposed, see the blog post of Sebastian Ruder for an overview.
Some machine learning problems can be casted as finding a Nash equilibrium in a min-max game (e.g. training generative adversarial networks) which can be tackle via extragradient methods or competitive gradient descent.
Natural Language Processing for low resource languages
Although many modern neural methods seem to work reasonably well, most of the ~6000-7000 languages spoken today lack resources for training. Therefore, there is a growing interest in natural language processing for low resource languages. As it is too difficult to give an overview of the field in a few lines, I advise you to check the following reviews:
Text generation
Text generation is an important problem in natural language processing that appears in many problems: machine translation, dialogue systems, paraphrase generation, text simplification, etc. The most common approach is based on autoregressive models where a sentence in generated one word after the other in sequential order. Unfortunately, computing the most probable output in this configuration is intractable, leading to the use of inexact greedy methods like beam search. A few research directions:
autoregressive models tend to assign high probability to degenerate outputs like the empty sentence. Sparse output distributions (instead of softmax based outputs) have been proposed to bypass this issue, and, in some cases, this also leads to an exact decoding algorithms; link 1 link 2
there is a mismatch between the training time objective (based on teacher forcing) and the test time algorithm (beam search). Alternative training methods have been proposed, for example based on a continuous relaxation of beam search or oracles; link 1 link 2 link 3
in many cases we want to generate diverse outputs, but just sampling from the output distribution is tricky and often leads to non-diverse results, therefore other techniques have been proposed. link 1 link 2
neural networks are difficult to control and this can be problematic in production when we want to be able to guarantee the quality of generated texts. One solution is to rely on templated text generation where templates are extracted automatically during learning. link 1 link 2
there is also an interest in non-autoregressive text generation. link